Welcome to Data Modeling
Introduction to data modeling
Data Science model: Artwork by @allison_horst
Class Objectives
- Understand the broad scope and importance of data modeling in predictive analytics and its impact on informed decision-making.
- Introduce the tidymodels framework, highlighting its comprehensive ecosystem designed to streamline the predictive modeling process in R.
The Importance of Data Modeling
Data modeling is an intricate process that leverages a multitude of techniques for analyzing historical data to make:
- well-informed predictions,
- accurate classifications, and
- insightful recommendations.
It forms the bedrock of data science and analytics, enabling the derivation of actionable insights from raw data.
This transformative process is pivotal in translating vast and intricate datasets into coherent, actionable insights that
- drive strategic decision-making,
- enhance operational efficiencies, and
- yield a competitive edge in the marketplace.
At its core, data modeling is about:
understanding the past
to make informed projections about the future.
It employs statistical analysis, machine learning algorithms, and computational techniques to sift through historical data, identifying underlying patterns, correlations, and trends.
These insights are then used to forecast future events, classify data into meaningful categories, and formulate recommendations that guide decision-making processes.
The Multifaceted Applications of Data Modeling
The applications of data modeling are vast and varied, spanning across industries and functions.
Its significance is universally acknowledged, from enhancing customer experiences to revolutionizing scientific research.
Some key applications:
Forecasting Future Trends:
Data modeling is instrumental in predicting future occurrences, whether it’s anticipating market demand, forecasting stock prices, or predicting weather patterns.
These predictions allow organizations to prepare and adapt their strategies in anticipation of future changes, ensuring they remain ahead of the curve.
Optimizing Business Strategies:
By harnessing the power of data modeling, businesses can optimize their operations and strategies for maximum efficiency and effectiveness.
This could involve allocating resources more efficiently, streamlining supply chains, or personalizing marketing efforts to target consumers more effectively.
Data-driven strategies empower businesses to make informed decisions that bolster growth and profitability.
Enhancing Decision-Making:
Data modeling provides a quantitative basis for decision-making, offering insights that help reduce uncertainty and risk.
By understanding the likely outcomes of different decisions, leaders can choose paths that align with their objectives and risk tolerance.
Driving Innovation and Discovery:
Beyond its practical applications in business and industry, data modeling is a cornerstone of scientific research and technological innovation.
It facilitates the discovery of new knowledge, the development of innovative products and services, and the exploration of new frontiers in science and technology.
Understanding Complex Patterns:
In the era of big data, the ability to navigate and make sense of complex data patterns is invaluable.
Data modeling unravels these patterns, revealing insights that can lead to breakthroughs in understanding consumer behavior, societal trends, and even biological processes.
The Strategic Edge
In a world inundated with data, the ability to effectively model and interpret this data is a key differentiator for businesses and organizations.
Data modeling elevates strategic planning and operational decision-making from intuition-based to data-driven, marking a transition towards more agile, responsive, and efficient operations.
It is not merely a tool for gaining insights but a strategic asset that enables organizations to:
- innovate,
- compete, and
- thrive in their respective domains.
Types of Modeling:
Modeling techniques can be broadly classified into four major categories, each serving a distinct purpose and employing different methodologies to analyze data and derive insights.
These categories are foundational to understanding the scope and application of data analytics in solving real-world problems.
Descriptive Modeling
Objective:
Descriptive modeling aims to summarize historical data to understand past behaviors, patterns, and trends.
It’s the first step in data analysis, providing a foundational understanding of the data at hand.
Applications:
Common applications include reporting sales numbers, marketing campaign performance, financial metrics, and customer demographics.
Descriptive models are used extensively in dashboards and reports to provide real-time insights into business operations.
Diagnostic Modeling
Objective:
Diagnostic modeling aims to find the causes behind observed patterns or trends.
It digs deeper into the data to determine why something happened.
This is crucial for understanding the factors contributing to a given outcome.
Applications:
Diagnostic models are often used:
in healthcare to identify the cause of a condition,
in marketing to determine which campaigns led to an increase in sales,
in customer analysis to understand the factors behind customer churn.
These models rely heavily on correlations and causal analysis to explain outcomes and inform decision-making.
Predictive Modeling
Objective:
Predictive modeling uses historical data to forecast future outcomes.
It identifies patterns and relationships in the data to make predictions about future events, behaviors, or states.
Predictive modeling is inherently probabilistic, providing predictions with associated uncertainty levels.
Applications:
It’s widely used for:
customer churn prediction,
credit scoring,
demand forecasting,
risk management (etc.)
Prescriptive Modeling
Objective:
Prescriptive modeling goes a step further than predictive modeling by not only forecasting future outcomes but also recommending actions to benefit from predictions.
It considers various possible decisions and identifies the best course of action.
Applications:
Prescriptive analytics is crucial in:
supply chain management,
optimizing resource allocation,
strategic planning,
operational efficiency.
It can suggest the best strategies for inventory management, marketing approaches, and even clinical treatment plans.
Why Predictive Modeling?
Predictive modeling is central to this course, emphasizing its vital role in forecasting future events and behaviors.
It leverages statistical and/or machine learning techniques to estimate unknown outcomes, crucial for strategic planning and decision-making across various sectors.
Key Aspects of Predictive Modeling:
When considering predictive modeling, several additional factors and best practices are important to ensure the effectiveness and reliability of your models.
Incorporating these considerations can enhance model performance and applicability to real-world scenarios:
Feature Engineering:
Crucial for Model Performance:
The process of creating new input features (independent variables) from your existing data can significantly enhance model accuracy by providing additional context and information.
Domain Knowledge Integration:
Leveraging domain knowledge to create meaningful features can uncover relationships that generic models might miss.
Model Interpretability:
Understanding Model Predictions:
Especially in sectors like finance and healthcare, understanding how and why a model makes certain predictions is crucial.
Techniques for improving model interpretability include using simpler models (when possible) and applying tools designed to explain model decisions.
Transparency and Trust:
Models that are interpretable foster trust among stakeholders and facilitate the implementation of model recommendations.
Handling Imbalanced Data:
Challenge in Classification Tasks:
Many real-world problems involve imbalanced datasets, where the classes are not equally represented.
This imbalance can bias the model toward the majority class, reducing its performance on the minority class.
Techniques for Addressing Imbalance:
oversampling the minority class,
undersampling the majority class, and
using specialized algorithms designed to handle imbalance.
Ethical Considerations and Fairness:
Bias and Fairness:
Models can inadvertently perpetuate or even exacerbate biases present in the training data.
It’s crucial to evaluate models for fairness and to take steps to mitigate any discovered biases.
Privacy Concerns:
Data used in modeling often includes personal information.
Ensuring data privacy and compliance with regulations (e.g., GDPR) is essential.
Model Deployment and Monitoring:
Operationalizing Models:
Deploying models into production requires careful planning, including considerations for scalability, latency, and integration with existing systems.
Continuous Monitoring:
Once deployed, models should be continuously monitored for performance drift and retrained as necessary to adapt to changes in the underlying data.
Collaboration and Communication:
Working with Stakeholders:
Effective communication with stakeholders about model capabilities, limitations, and performance is essential.
Collaborative model development ensures that the model meets the business needs and that stakeholders understand and trust the model’s predictions.
Documentation:
Comprehensive documentation of the modeling process, decisions made, and model performance metrics aids in transparency, reproducibility, and facilitates ongoing maintenance.
Incorporating these considerations into your predictive modeling projects
not only enhances model accuracy and reliability
but also ensures that your models are ethical, interpretable, and aligned with business objectives and regulatory requirements.
Introduction to tidymodels
tidymodels is a collection of R packages that provides a comprehensive framework for modeling, designed to work seamlessly within the tidyverse ecosystem.
It simplifies and standardizes the process of building, tuning, and evaluating models, making predictive modeling more accessible and reproducible.
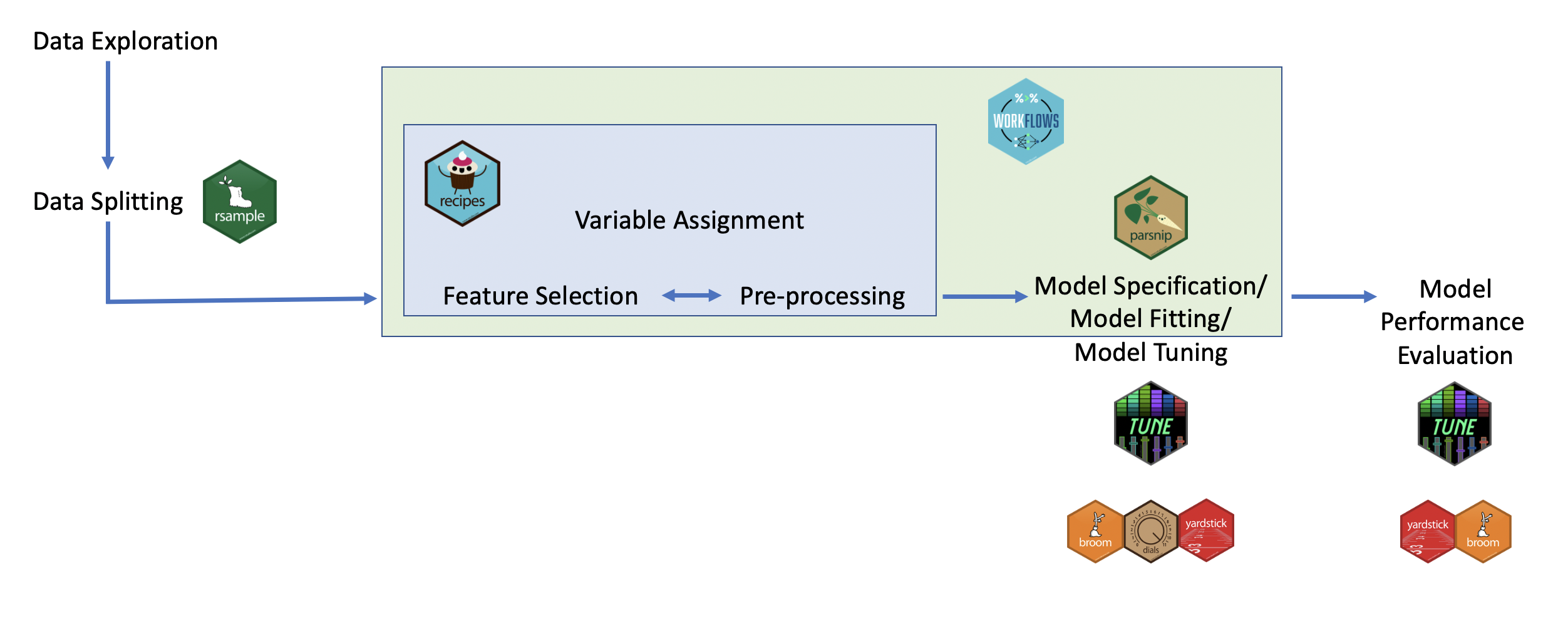
Tidymodels in Action
Introduction to the tidymodels ecosystem
The ecosystem includes packages like:
recipes = Data Preprocessing
Facilitates the creation of preprocessing steps for data, including feature engineering, normalization, and handling missing values.
Enables the specification of a series of preprocessing operations to prepare data for modeling systematically.
parsnip = Model Specification
Provides a unified interface to specify a wide array of models from different packages without getting into package-specific syntax.
Allows for easy model switching and comparison by standardizing model syntax.
workflows = Streamlining Model Fitting
Combines model specifications and preprocessing recipes into a single object, simplifying the process of model training and prediction.
Ensures that the preprocessing steps are applied consistently during both model training and prediction phases.
tune = Hyperparameter Optimization
Supports the tuning of model hyperparameters to find the optimal model configuration.
Integrates with resampling methods to evaluate model performance across different hyperparameter settings systematically.
yardstick = Model Evaluation
Offers a suite of functions to calculate performance metrics for models, such as accuracy, RMSE, and AUC, among others.
Allows for a consistent and straightforward way to assess and compare model performance.
broom = Tidying Model Outputs
Helps in converting model outputs into tidy formats, making them easier to work with within the tidyverse.
Provides functions to extract model statistics, performance measures, and other relevant information in a user-friendly structure.
Recap
Each component of the tidymodels ecosystem is designed to address specific aspects of the model building and evaluation process, making it easier for data scientists to develop, tune, and deploy models efficiently and effectively.
Together, these packages offer a comprehensive framework that enhances the modeling workflow in R, adhering to the principles of tidy data and reproducible research.
So, why tidymodels?
- Consistency: Offers a unified interface for various modeling tasks.
- Integration: Fully compatible with tidyverse packages for data manipulation and visualization.
- Flexibility: Supports a wide range of statistical and machine learning models.